La versión 2016 de SSAS (Analysis Services) ha incorporado muchas funciones DAX, entre ellas SUMMARIZECOLUMNS, función que podemos encontrar en Power Pivot de Excel 2016 y Power BI.
Es una función que en aplicaciones reales la he encontrado mejores tiempos de respuestas que la combinación CALCULATETABLE + ADDCOLUMNS + SUMMARIZE.
Es muy util cuando usamos DAX como lenguaje de consulta o para armar una tabla dentro de SSAS Tabular, funcionalidad disponible en SSAS 2016 en modo de compatibilidad 1200, en Power BI y Power Pivot de Excel 2016, pero esto de tablas es para otro día…
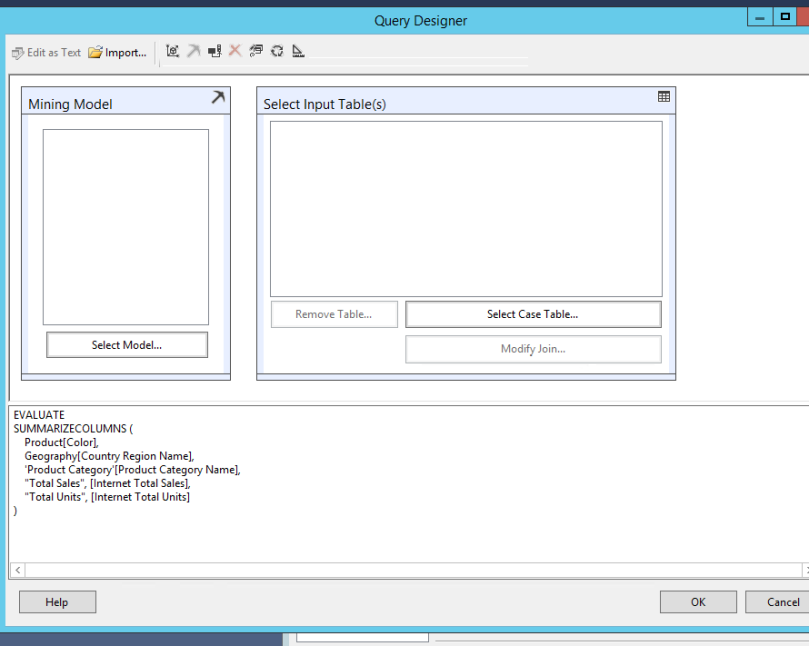
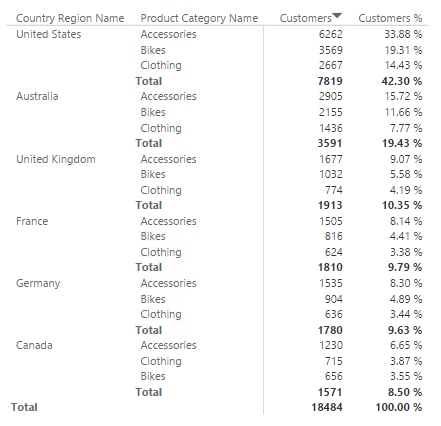
Cuando podríamos usar esta función, cuando armamos reportes con Reporting Services, ya sea en reportes paginados, reportes móviles o KPIs, estos dos últimos antes conocidos como Datazen e incorporados en SSAS 2016 EE.
Esta function retorna una tabla, y posee la siguiente sintaxis
SUMMARIZECOLUMNS
(
<groupBy_columnName>[, < groupBy_columnName >]…,
[<filterTable>]…
[, <name>, <expression>]…
)
La función posee tres areas o tipos de parámetros principales:
- Campos de agrupación
- Condiciones de filtro
- Expresiones o cálculos
He aqui algunos ejemplos sencillos para empezar
Ejemplo 1:
EVALUATE
SUMMARIZECOLUMNS ( Product[Color] )
Este ejemplo inicial nos devuelve todos los diferentes valores de la columna Color de la tabla Product
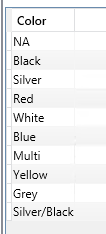
Ejemplo 2:
EVALUATE
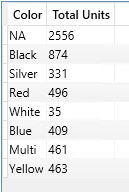
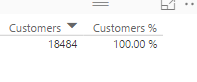
SUMMARIZECOLUMNS ( Product[Color], "Total Units", [Internet Total Units] )
Este segundo ejemplo nos devuelve una tabla con totales por color, como podemos ver la funcion solo retorna los valores con datos, es decir, usa las expresiones para determianr si mostrar un registro o no.
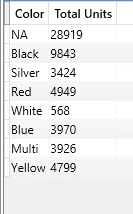
Ejemplo 3
EVALUATE
SUMMARIZECOLUMNS (
Product[Color],
"Total Units", IGNORE( [Internet Total Units])
)
En este ejemplo usamos la funcion IGNORE que nos permite indicar a la funcion SUMMARIZECOLUMNS que no use esa expresion para determinar la existencia o no de datos.
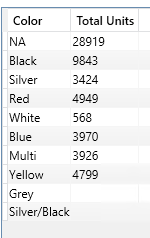
Ejemplo 4
EVALUATE
SUMMARIZECOLUMNS (
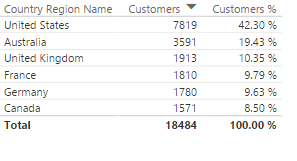
Product[Color],
FILTER( Geography, Geography[Country Region Name] = "Germany" ),
"Total Units", [Internet Total Units]
)
En este ejemplo agregamos una condición de filtro, que no necesariamente debe ser sobre un campo o tabla que estemos utilizando en los campos de GROUP BY pero si debe estar afectado a la expression.